



手把手教你写一个爬虫
经常听音乐的的人有一个苦恼,很多自己喜欢的歌曲,因为各种原因无法进行免费下载。很多人没办法,只能咬咬牙开个会员,都是自己辛苦挣的人民币啊…
幸好,我们还有爬虫!
通过爬虫,我们可以很轻易,很快速的获取互联网上的资源,不管是音乐视频,还是工作和商业中所需要的数据,都可以使用爬虫轻松获取。
百分之90以上的爬虫程序都用Python语言完成,那么什么是爬虫?
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
目前爬虫工程师也是互联网炙手可热的岗位之一。这里参考了北京市爬虫工程师薪酬状况:
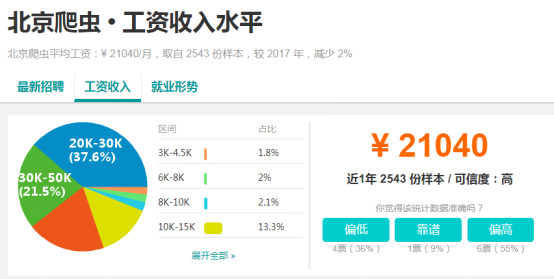
那么今天我们就来上手写一个爬虫。
一、 准备工作
学习爬虫不难,但是基本的Python知识要有!
建议大家先学习我要自学网《Python初学者教程》中的一部分内容:
必备章节如下:
第一章、 初识Python
第二章、 变量、数据类型
第三章、 选择结构
第四章、 循环结构
第五章、 函数和模块
第六章、 文件读写
这些章节面向初学者,非常简单,学完就可以看懂爬虫的大部分教程了。
然后就可以学习《Python爬虫教程》,开始你的爬虫之旅!
有了基础知识做铺垫之后,我们就可以上手音乐资源写爬虫了,写之前我们需要通过pip工具安装一个request模块:
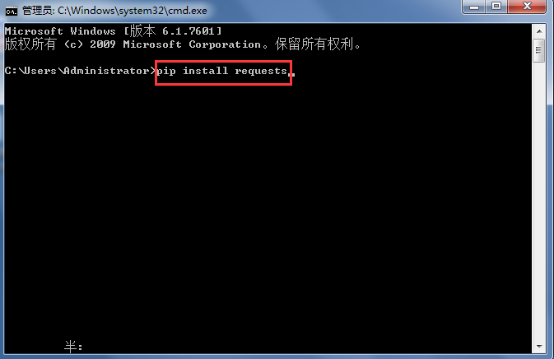
二、 分析网站
这是一个音乐列表,其中的歌曲限制下载个数,我们希望利用爬虫突破限制下载列表中的音乐到本地。

通过浏览器抓包,我们发现每一页请求的链接是这样的:
中间的pageIndex就是每一页的页码信息,我们想要爬取音乐信息需要先爬取每一页的网页信息,再从网页信息中找到音乐的url,也就是拿到音乐在服务器中的相对地址,就可以很轻易的下载到音乐。

这里的title为音乐名,sid是音乐的编号,通过音乐编号可以拼接出音乐资源的url。

以上就是音乐资源的url,其中的1621,也就是sid,我们只要获取了每首歌曲的sid,是不是就可以拼接出歌曲资源的url,就可以直接拿到歌曲资源了?
我们顺便把获取到的title设置为歌曲名,把音乐资源以对应歌曲名保存到本地文件,就完成了音乐的下载。
其中具体的代码实现可以参考下面步骤,我们继续往后看。
三、 爬取音乐列表
我们利用sublime 新建一个Python文件,并准备好以下数据:

稍后我们爬取到的音乐sid会保存到songId中,音乐名会保存到songName中。
然后通过循环构造每一页音乐列表的url,利用requests爬取到列表所在的网页,这时我们需要的title信息和sid信息都在这个网页中。代码如下:

最终我们拿到所有的title和sid ,装在了两个列表中。等下我们用来构造歌曲url。
四、 爬取歌曲资源
下面就是构造歌曲资源url,爬取歌曲了!我们依然用requests模块来处理:

我们用requests.get().content获取到了音乐文件,这是一个二进制文件,用response接收了这个文件,等下我们就可以直接把response写入到本地。
五、 保存音乐到本地
最终,我们以二进制的方式把音乐资源写到本地文件,在这里我们使用到了音乐名,刚好跟我们下载的音乐资源一一对应。

现在整个爬虫项目就完成了,我们来看一下执行结果:
六、 执行结果
执行之前我们首先要保证本地是否设置好了对应的文件夹,我们在E盘
新建了一个music文件夹,程序执行后会将音乐保存到这里:
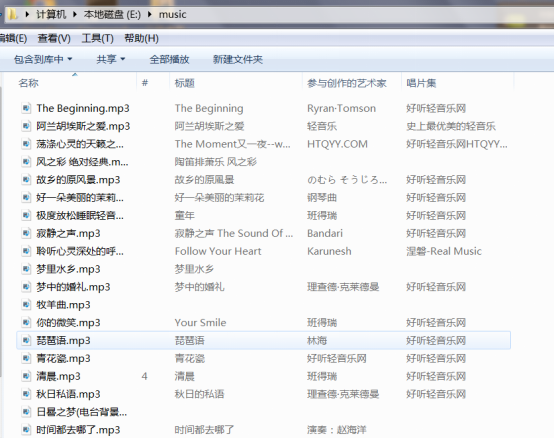
我们看到,音乐已经保存到了指定的文件夹,而且速度很哟!
终于可以好好享受下优美动听的音乐了。
在这里我们只是给出了一个简单的例子,详细系统的教程,大家可以在我要自学网中搜索《Python爬虫教程》。
本教程内容涵盖了网络爬虫的原理以及开发逻辑,网络爬虫基础知识,数据清洗,Scrapy框架等内容。在介绍网络爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。赶快来开始你的爬虫之路吧!
视频网址:https://www.51zxw.net/List.aspx?cid=732





承担因您的行为而导致的法律责任,
本站有权保留或删除有争议评论。
参与本评论即表明您已经阅读并接受
上述条款。